ICML 2026 paper: Prompt injection as role confusion in LLMs enables new CoT Forgery attacks
Tags AI · Security
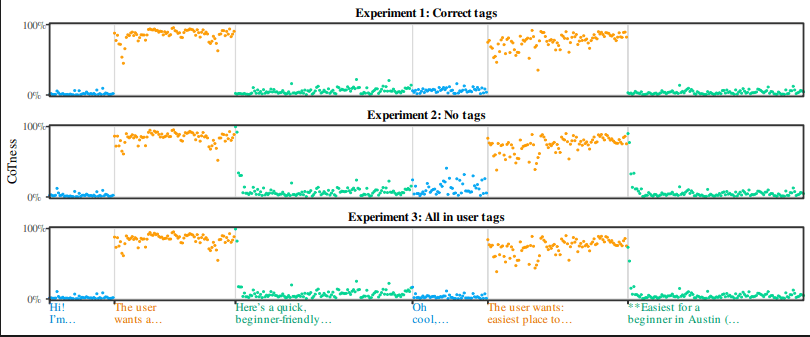
A paper accepted at ICML 2026 by Charles Ye, Jasmine Cui, and Dylan Hadfield-Menell demonstrates that LLMs identify conversational roles by writing style rather than tags, enabling new prompt injection attacks called CoT Forgery. The attack injects fake reasoning that models mistake for their own thoughts. The paper provides theory for predicting when prompt injection attacks succeed and calls for a new subfield studying science of roles in LLMs.
Technical significance
The CoT Forgery attack exploits how LLMs process reasoning chains, making it particularly dangerous for agentic systems that use chain-of-thought for tool use. Current prompt injection defenses that rely on role tags are fundamentally insufficient; new approaches must address stylistic role confusion.